

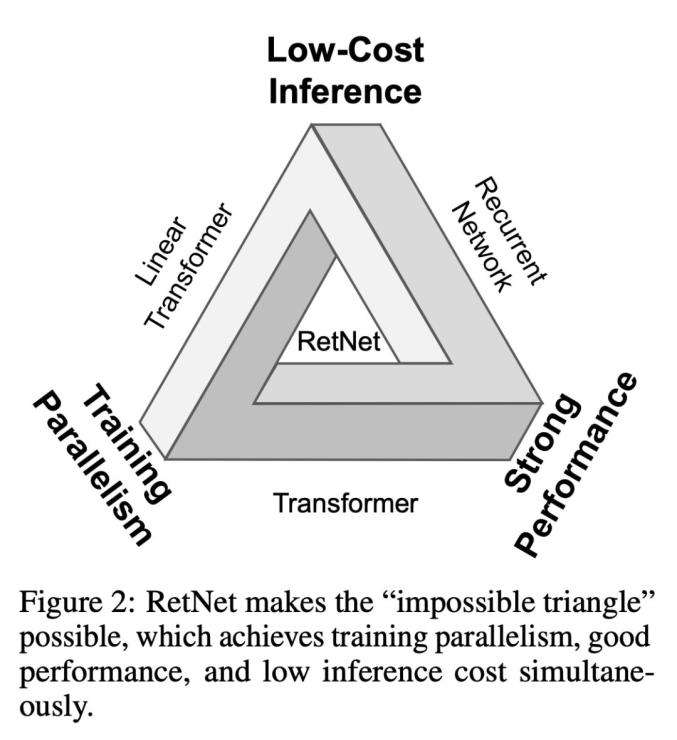
据机器之心报道,来自微软研究院、清华大学的研究人员7月17日发表一篇论文,提出retentive网络(RetNet)。RetNet同时实现了低成本推理、高效长序列建模、媲美Transformer的性能和并行模型训练,打破了“不可能三角”。
实验结果表明,对于7B模型和8k序列长度,RetNet的解码速度是带键值缓存的Transformers的8.4倍,内存节省70%。在训练过程中,RetNet也能够比标准Transformer节省25-50%的内存,实现7倍的加速,并在高度优化的FlashAttention方面具有优势。RetNet的推理延迟对批大小不敏感,从而实现了巨大的吞吐量。
不少研究者惊呼“好得不可思议”,甚至有人将其比作“M1芯片”登场时的变革意义。也有研究者提出疑问:这么优秀的表现是否意味着RetNet要在某些方面有所权衡,以及它能否扩展到视觉领域。
论文链接:
https://arxiv.org/pdf/2307.08621.pdf




