今日凌晨,Meta宣布推出首个“类人(human-like)”AI模型I-JEPA。这是第一个基于Meta首席AI科学家杨立昆(Yann LeCun)愿景关键组成部分的AI模型,据称能比现有模型更准确地分析和完成未完成的图像。
在上周举办的背景智源大会上,杨立昆在发表致辞演讲时斗志昂扬地驳斥了GPT的逻辑,说自回归模型没有规划、推理的能力,单纯根据概率生成自回归的大语言模型从本质上根本解决不了幻觉、错误的问题,并给出了他认为的正确答案——世界模型。
杨立昆去年提出了一种新的架构,旨在克服当今最先进的AI系统的关键限制。他的愿景是创造出能够学习世界如何运作的内部模型的机器,这样它们就可以更快地学习,计划如何完成复杂的任务,并随时适应不熟悉的情况。
基于LeCun愿景关键组成部分,今日发布的图像联合嵌入预测架构(I-JEPA),通过创建外部世界的内部模型来学习,该模型比较图像的抽象表示(而不是比较像素本身)。
I-JEPA在多个计算机视觉任务上提供了强大的性能,并且比其他广泛使用的计算机视觉模型的计算效率高得多。I-JEPA学习的表示也可以用于许多不同的应用程序,而不需要进行大量的微调。
例如,Meta研究人员在72小时内使用16个A100 GPU训练了一个拥有6.32亿个参数的视觉Transformer模型,并且它在ImageNet上实现了最先进的少样本分类性能,每个类只有12个标记示例,其他方法通常需要2到10倍以上的GPU时,并在使用相同数量的数据进行训练时获得更低的错误率。
I-JEPA相关论文将在下周的CVPR 2023上发表,训练代码和模型检查点的源代码已开放。

论文地址:
https://arxiv.org/pdf/2301.08243.pdf
项目地址:
https://github.com/facebookresearch/ijepa
Meta AI博客文章全文编译如下:
01.
通过自监督学习获取常识性知识
Meta在I-JEPA(以及更普遍的联合嵌入预测架构(JEPA)模型)上的工作基于这样一个事实:人类通过被动地观察世界来学习大量关于世界的背景知识。
据推测,这种常识性信息是实现智能行为的关键,例如样本高效获取新概念、基础和计划。
AI研究人员试图设计学习算法,捕捉有关世界的常识背景知识,然后将其编码为算法以后可以访问的数字表示。
为了提高效率,系统必须以自监督的方式学习这些表征——也就是说,直接从图像或声音等未标记的数据中学习,而不是从人工组装的标记数据集中学习。
在较高的层次上,JEPA旨在通过相同输入的其他部分的表示来预测输入部分(如图像或文本)的表示。因为它不涉及将图像的多个视图/增强表示折叠到单个点,所以希望JEPA能够避免与另一种广泛使用的称为基于不变性的预训练的方法相关的偏差和问题。
与此同时,通过在高抽象水平上预测表征,而不是直接预测像素值,Meta希望直接学习有用的表征,同时避免生成方法的局限性,这是大型语言模型的基础,最近已经产生了如此多令人兴奋的进展。
相比之下,生成式架构通过删除或扭曲模型输入的部分来学习,例如删除照片的一部分或隐藏文本段落中的一些单词。然后,他们尝试预测损坏或丢失的像素或单词。
然而,生成式AI方法的一个显著缺点是,模型试图填补每一点缺失的信息,即使世界本身是不可预测的。因此,生成式AI方法可能容易犯一些人们永远不会犯的错误,因为它们过于关注不相关的细节,而不是捕捉高层次的可预测概念,例如生成式AI模型很难准确地生成人手。(他们经常会添加额外的数字或犯其他明显的错误。)
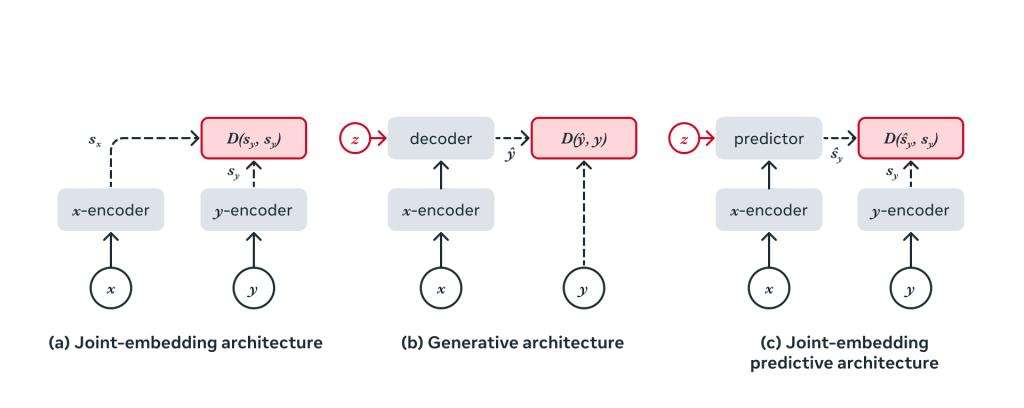
▲自监督学习的通用架构,其中系统学习捕捉其输入之间的关系。目标是为不兼容的输入分配一个高能量,并为兼容的输入分配一个低能量。(a) 联合嵌入(不变)体系结构学习为兼容输入x、y输出相似嵌入,为不兼容输入输出不同嵌入。(b) 生成式架构学习从兼容信号x直接重构信号y,使用以附加(可能是潜在的)变量z为条件的解码器网络来促进重构。(c) 联合嵌入预测架构学习从兼容信号x中预测信号y的嵌入,使用以附加(可能是潜在的)变量z为条件的预测网络来促进预测。
02.
迈向具有广泛功能的
联合嵌入预测架构的第一步
I-JEPA背后的想法是用一种更接近于人们一般理解的抽象表示来预测缺失的信息。
与在像素/标记空间进行预测的生成方法相比,I-JEPA使用抽象的预测目标,可以消除不必要的像素级细节,从而使模型学习更多的语义特征。引导I-JEPA生成语义表示的另一个核心设计选择是提出的多块屏蔽策略。
具体来说,Meta研究人员证明了使用信息(空间分布)上下文预测包含语义信息(具有足够大的规模)的大型块的重要性。
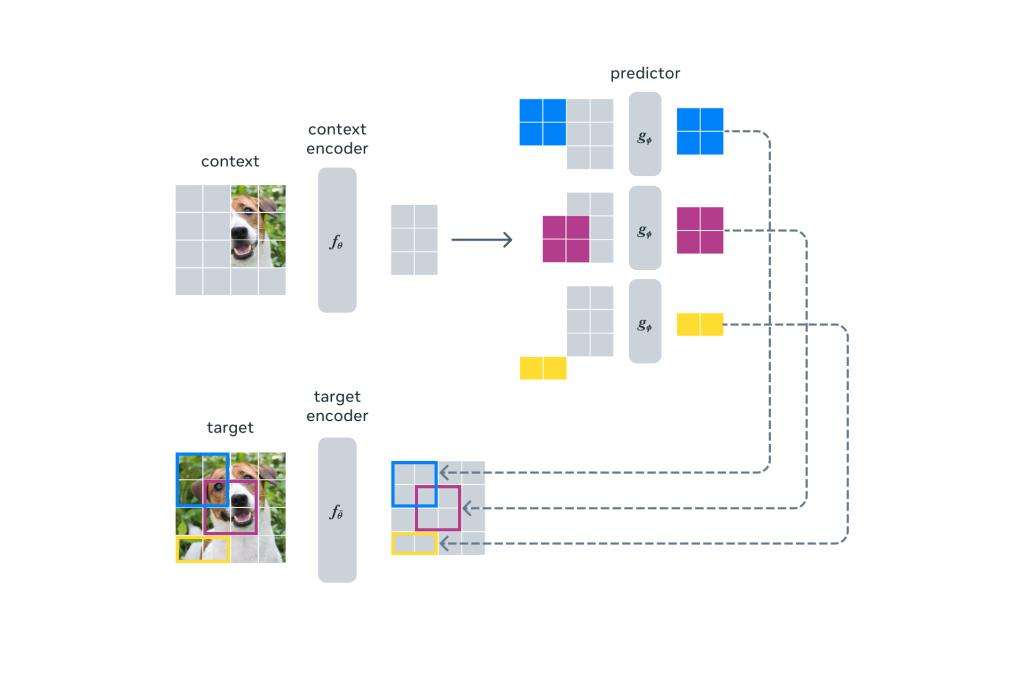
▲I-JEPA使用单个上下文块来预测来自同一图像的各种目标块的表示。上下文编码器是一个视觉Transformer(ViT),它只处理可见的上下文补丁。预测器是一个狭窄的ViT,它接受上下文编码器的输出,并根据目标的位置标记(以颜色显示)来预测目标块在特定位置的表示。目标表示对应于目标编码器的输出,其权重通过上下文编码器权重的指数移动平均值在每次迭代中更新。
I-JEPA中的预测器可以看作是一个原始的(受限制的)世界模型,它能够从部分可观察的环境中对静态图像中的空间不确定性进行建模。更重要的是,这个世界模型是语义的,因为它预测图像中未见区域的高级信息,而不是像素级的细节。

▲说明了预测器是如何学习对世界的语义建模的。对于每个图像,蓝色框外的部分被编码并作为上下文提供给预测器。预测器输出它在蓝色框内的区域中所期望的表示。为了可视化预测,我们训练了一个生成模型,该模型生成由预测器输出表示的内容的草图,并且我们在蓝色框中显示了一个示例输出。显然,预测器能够识别应该填充哪些部分的语义(狗的头顶、鸟的腿、狼的腿、建筑物的另一边)。
为了理解模型捕获的是什么,Meta训练了一个随机解码器,它将I-JEPA预测的表示映射回像素空间,当在蓝色框内进行预测时,它显示了模型的输出。这种定性评估表明,该模型正确地捕捉了位置的不确定性,并产生了具有正确姿势的高级物体部件(例如,狗的头,狼的前腿)。
简而言之,I-JEPA能够学习对象部件的高级表示,而不会丢弃它们在图像中的局部位置信息。
03.
更高的效率和强大的性能
I-JEPA预训练的计算效率也很高。它不涉及与应用更多计算密集型数据增强来生成多个视图相关的任何开销。目标编码器只需处理图像的一个视图,并且上下文编码器只需处理上下文块。
根据经验,Meta发现I-JEPA无需使用人工制作的视图增强即可学习强大的现成语义表示(参见下图)。它在ImageNet-1K线性探测和半监督评估上也优于像素和标记重建方法。
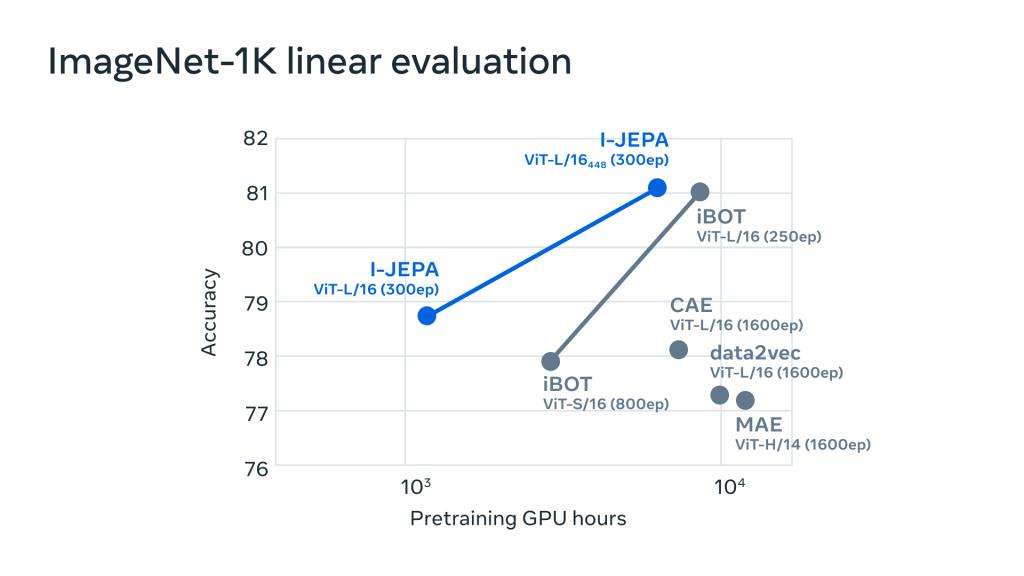
▲ImageNet-1k上的线性评估性能作为GPU预训练小时数的函数。
I-JEPA还与以前依赖于语义任务上手工制作的数据增强的预训练方法相竞争。与这些方法相比,I-JEPA在物体计数和深度预测等低级视觉任务上取得了更好的性能。
通过使用更简单的模型和更少的刚性归纳偏差,I-JEPA适用于更广泛的任务集。
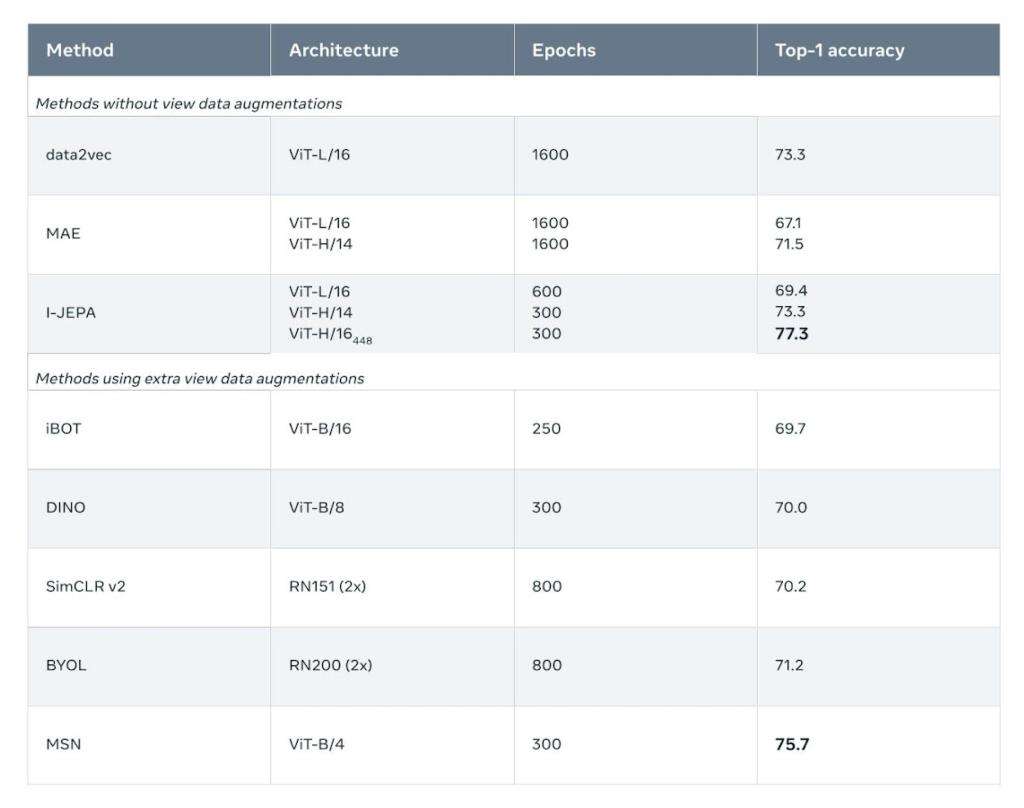
▲低镜头分类精度:在ImageNet-1k上使用1%的标签进行半监督评估(每个类大约12个标记图像)。
04.
结语:人工智能向人类水平迈进了一步
I-JEPA展示了学习竞争性现成图像表示的架构的潜力,而不需要通过手工制作的图像转换编码额外的知识。
推进JEPAs从更丰富的模式中学习更一般的世界模型将是特别有趣的,例如,使人们能够从短上下文中对视频中的未来事件做出长期的空间和时间预测,并根据音频或文本提示调节这些预测。
Meta研究人员期待着将JEPA方法扩展到其他领域,如图像-文本配对数据和视频数据。
未来,JEPA模型可能会在视频理解等任务上有令人兴奋的应用。这是应用和扩展自监督方法来学习世界一般模型的重要一步。