11月8日上午,上海市互联网业联合会2023年度第四期“前沿讲坛”在上海对外经贸大学举行。大成(上海)律师事务所合伙人赵云虎律师作了“人工智能对法律的挑战及构建可信的人工智能”主题演讲,并宣布大成(上海)律师事务所将为中小企业在人工智能运用中遇到的法律问题提供免费咨询服务。
本次讲坛聚焦人工智能广泛应用带来的新的法律、伦理、道德及社会治理问题,探讨构建可信的人工智能的可能性。赵云虎律师还通过多起国内外典型案件,解析AI生成作品版权、开源软件相关的司法实践。
AI造假、算法歧视?新智能面临新挑战
“一个购物推荐的AI可能会根据用户的个人信息偏好,对同样的商品或服务向不同的用户定价或给予不同的优惠。”赵云虎律师指出,AI模型的训练依赖于大量的数据,而这些数据可能存在包含偏见、不公平或歧视的内容。如果训练数据中存在对某些群体的偏见或不平等对待,AI模型在生成内容时也可能体现这些偏见。如果训练数据不足或不具有代表性,模型也可能无法准确地理解和反映各个群体的多样性和差异性,从而导致生成内容存在歧视性。AI模型缺乏人类的监督和纠正机制,就无法主动识别和纠正内容中的偏见和歧视,进一步加剧了算法歧视问题。
同时,根据对AIGC质量评估的最新研究,以生成式大模型为代表的生成式人工智能可能会被利用生成含有新犯罪内容的技术工具、被利用获取犯罪方法以及自主实施违法行为的风险。
在用户恶意诱导下,生成式大模型可能会被利用编写功能即时生成诈骗软件,生成发布有关如何制作或销售枪支弹药毒品等各类违禁管制物品的违法犯罪信息。投射在商业领域,可能会因信息误导引发股票市场动荡,或因信息不实影响商家和产品信誉严重扰乱市场秩序,涉嫌构成损害商业信誉、商品声誉罪。
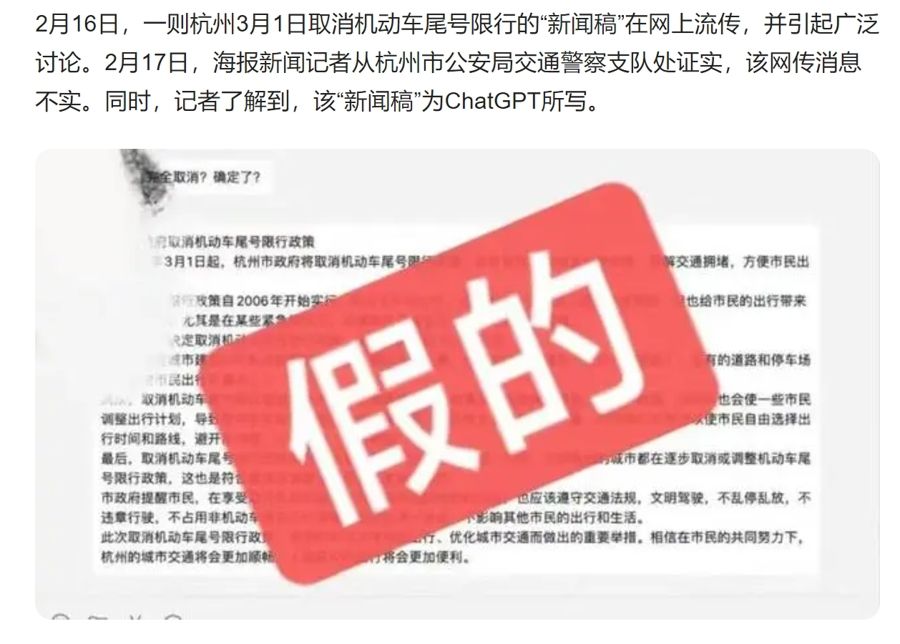
生成式大模型还可能会制造和宣传虚假信息。
在社会层面上,生成式大模型还可能会制造和宣传虚假信息,引起网络谣言的传播,构成对公民个人信息权、隐私权、名誉权的侵犯,情节严重的可能会涉嫌构成诬告陷害罪、侵犯公民个人信息罪等。
赵云虎指出,生成式人工智能既存在数据源上的“虚假”,也存在内容生成过程中的“虚假”,“生成式人工智能技术根据其基本原理,实际上很大程度上是一个算法黑箱,人们能够看到的是输入和输出两端,但中间的工作原理和机制并不清楚,它的结果是靠算力‘烧’出来的,并没有经验性的总结”。
如何构建可信赖的人工智能
我国颁布的《生成式人工智能服务管理暂行办法》在算法、内容、应用、数据安全等方面对生成式人工智能进行了全面的规制。在赵云虎看来,依据此文件,数据提供者、算法/模型开发者以及服务提供者可以采取多种方式共同构建可信赖的人工智能。
对于数据提供者而言,赵云虎建议,要规范数据采集活动,明确合同责任约定。比如,在爬取公开的、非保密的数据时,不应爬取非公开的后台数据;如果目标网站有反爬取协议,应严格遵守网站设置的 Robots协议;应避免使用破解密码、伪造IP、伪造UA等技术手段以规避或破解网站采取的保护数据的技术措施。

赵云虎律师通过多起国内外典型案件,解析AI生成作品版权、开源软件相关的司法实践。
对于履行备案义务的算法/模型开发者而言,赵云虎认为,应遵守备案规定,按要求履行备案手续,并在需要时进行变更或注销备案手续。在AI研发的过程中,开发者应当采取措施以确保在整个流程中能够对AIGC的使用情况进行可控、可见、可审计和可追溯的管理(即透明性),制定详细的标注指南,加强对标注人员的培训,对标注情况进行质量控制。在与数据使用方之间建立合同或数据使用协议时,明确约定双方的权利和责任。包括数据的使用范围、数据保护措施、违约责任等内容。
作为服务提供者,赵云虎从算法、内容、数据、用户的合规管理上给出了具体建议。例如,要确保生成内容积极向上、宣扬社会正能量,符合道德、法律和伦理的要求;建立强化的虚假信息识别机制,通过算法和技术手段,尽量避免生成虚假信息的内容。通过过滤和验证机制,提高生成内容的真实性和可信度。在生成的内容中,恰当地标注其来源和生成方式,使用户能够辨识出其为生成式人工智能创作的内容,“这都有助于用户理解和判断内容的可信度和真实性。”
此外,赵云虎提醒,企业如果打算在内部使用生成式人工智能工具,建议开展使用培训,并在员工手册或其他内部制度中规定禁止输入保密信息或未公开的内容。同时应当避免直接依赖生成式人工智能的输出结果采取行动,而应在采取行动之前对其输出结果进行人工审查。