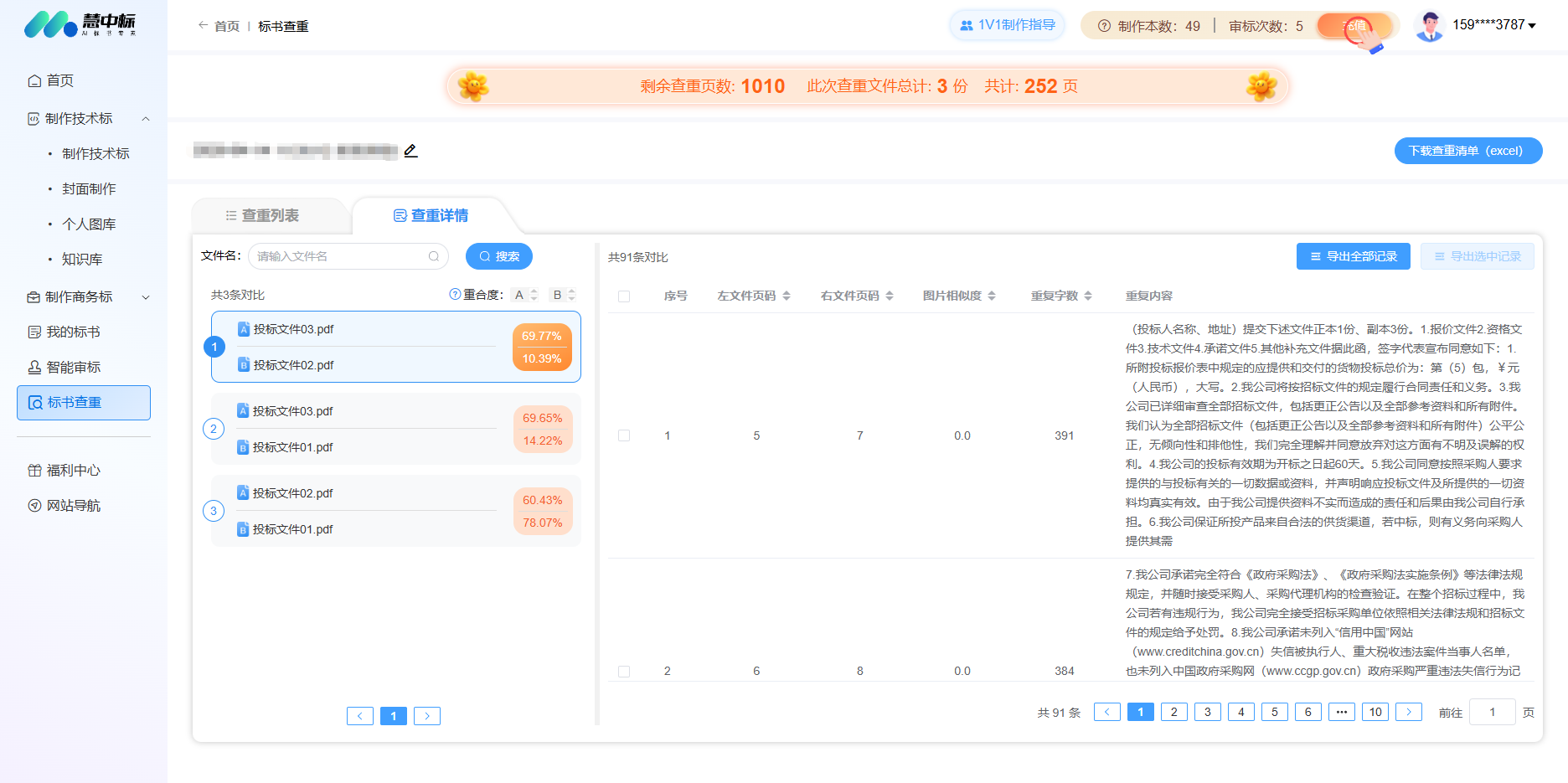
“缺乏特定领域或能力的数据是制约 AI 是否表现优秀的关键因素。”

什么是AI语料库?
要运行一个AI人工智能项目需要算法、算力、数据三要素, 这里提到的数据,即语料库。指的是用于训练人工智能的内容“主体”或数据集合。
ChatGPT 详细说明了其语料库中的数据类型。我们可以看到 ChatGPT 的语料库主要来自于:
- 网站:来自不同领域和主题的网站的文本。
- 书籍:来自涵盖各种类型和主题的各种书籍的文本。
- 文章:来自新闻文章、杂志专题和博客文章的文本。
- 研究论文:来自科学论文和出版物的文本。
- 对话数据:来自对话、对话和交互的文本。
- 社交媒体:来自Twitter、Reddit 和在线论坛等平台的文本。
- 维基百科:来自涵盖众多主题的维基百科文章的文本。
如果没有语料库来喂养人工智能,人工智能就无法学习。语料库越大,人工智能就会变得越熟练或越智能。但当涉及到版权和知识产权法时,构成人工智能语料库的实际数据却带来了全新的麻烦。 所以,除了公开的数据外,每一个公司或组织还有大量私有的数据,这些私有的数据可以用于训练局部的模型,用于授权范围的使用。
语料库是决定 AI 是否智能的关键因素
最近我们发现越来越多的AI 大语言模型出现,接近百模大战,新闻出多了,大家也都不怎么关心了。
刚开始的时候,大家还非常在乎哪一个模型有多少参数,谁的模型参数大,大了多少,后来大家发现这个比参数的过程已经不那么重要了,这个就好比大家都造了一辆车,然后我的启动速度是3.6秒你的是3.2秒,已经完全没有作比较的意义,他并不影响模型在应用过程当中有更好的表现。
著名的 OpenAI 的工程师 James Betker,著名”文生图”模型 DALL-E 的第一作者。在他的一篇博客文章中就这提到,在他的日常开发大模型过程中,到某个阶段后不管怎么增加参数,调整方法,模型的效果都不如给模型投喂更多的语料来得显著,更多的训练材料和更新颖的语料会显著的提升模型的效果。而更神奇的是,针对不同的模型,如果拿同样的语料去训练,他们最终的表现居然惊人的相似,这也证明了语料库的差异化才是决定大语言模型差异的关键因素。
👏缺乏特定领域或能力的数据是制约 AI 是否表现优秀的关键因素。
这个结论一下也非常容易理解,AI模型的最终目标,也就是在模仿人类的思维,而语料代表了他所涉及的知识,我们不同的人看过不一样的书,学到不一样的知识,最终他的表现也各不一样。

这就好比我们找不同的学生来解一道数学题,最终大家都能够解出来,只是不同的学生解出的方法和思路各不一样。或者找一些专业的画家来临摹一个模特,如果目标就是复原这个模特的真实样貌,那么只要画家达到一定的水准,不管谁来画结果都非常的相近,因为模特长相是不变的。这就告诉我们两个观点:
- 谁家的公司数据足够多,质量足够好,他的模型就会强于其他公司
- 开源模型完全可以替代闭源模型,前提是训练的语料要足够的多。
下面是 James Betker 的原文,翻译自他本人的博客: Non_Interactive –nonint.com。
人工智能模型中的“它”是数据集。
发表于2023 年 6 月 10 日2023 年 6 月 10 日来自jbetkerjbetker
我在 OpenAI 工作了将近一年。在这段时间里,我训练了很多生成模型。训练的模型数量比任何人都多。我花了几个小时观察调整各种模型配置和超参数的效果,其中让我印象深刻的一件事是所有训练运行之间的相似性。
我越来越清楚,这些模型确实在令人难以置信的程度上近似它们的数据集。这意味着它们不仅了解了狗或猫的含义,还了解了分布之间无关紧要的间隙频率,例如人类可能拍摄的照片或人类经常写下的单词。
这表明——在同一个数据集上训练足够长的时间后,几乎每个具有足够权重和训练时间的模型都会收敛到同一点。足够大的扩散卷积网络产生的图像与 ViT 生成器相同。AR 采样产生的图像与扩散相同。
这是一个令人惊讶的观察!这意味着模型行为不是由架构、超参数或优化器选择决定的。它是由您的数据集决定的,而不是其他任何东西。其他一切都是为了有效地交付计算以近似该数据集。
那么,当你提到“Lambda”、“ChatGPT”、“Bard”或“Claude”时,你指的不是模型权重。而是数据集。
语料库的商业价值
语料库中的文本数据可以用于信息抽取和知识图谱构建。通过从文本中提取实体、关系和事件等信息,并将其组织成结构化的知识图谱,可以支持智能搜索、问答系统和知识管理。

近年来,随着AI模型训练的需求推动语料库也得到了非常强的发展。独有的、大量的、完备的语料库数据集具有很高的价值。比如埃隆·马斯克想要为他摇摇欲坠的 Twitter 带来新的收入来源,他可能会考虑将平台上的所有推文打包到一个语料库中,然后出售给人工智能初创公司。 Meta 的 Facebook 也将在此找到新的收入来源。事实上,Reddit 的用户帖子语料库已被用来帮助训练 ChatGPT,从中获利上千万美元(见 36Kr: 天下再无免费数据?“美版贴吧”向AI公司收取数据使用费)。
👌谷歌与 Reddit 达成人工智能培训协议: 通过合作,谷歌可以使用Reddit的数据应用编程接口(API),该接口提供来自Reddit平台的实时内容,允许访问Reddit的大量内容,并能在谷歌的产品中显示Reddit的内容,这项合同价值约每年 6000 万美元。
从这个意义上说,随着越来越多的公司扩展到人工智能领域,强大的、预先打包的语料库在科技世界中可能会变得像镐对于淘金热时期的矿工一样重要,并且可能会出现一个全新的语料库卖家家庭手工业。
如果是这样的话,在未来的几个月和几年里,当我们谈论和辩论人工智能时,“语料库”将成为白话的常规组成部分。